这是关于构建具备可复用技能的 ADK 智能体系列文章(共 3 部分)的第一部分。
几周以来,我一直听说关于“智能体技能(Agent Skills)”的消息 —— 这种理念是赋予智能体模块化知识,并让它们按需加载,而不是将所有内容一股脑塞进系统提示词(system prompt)中。我甚至在 Gemini CLI 中使用过几个。但在浏览教程和 X 上的讨论串时,我始终面临着同一个问题:这种模式在 Google 的智能体开发工具包(ADK)中究竟能发挥多大作用?
Agent Skills 格式最初由 Anthropic 开发,作为开放标准发布,并已被越来越多的智能体产品所采用,包括 Claude Code、GitHub Copilot、Cursor、Gemini CLI、OpenAI Codex 以及更多。Google 发布了官方 ADK 开发技能,教导编码智能体如何编写 ADK 代码 —— 这种 SKILL.md 格式同时驱动着生态系统的开发端和运行时端。一种观点捕捉到了这种势头:“SaaS 正在被 SKILL.md 文件所取代” —— 这条推文在 X 上获得了 562 个互动。
我的第一个念头是:Skills 是否只是 MCP 的另一种表现形式?在阅读了 agentskills.io 概览后,两者的区别变得清晰起来。MCP 让智能体能够访问外部工具和数据 —— 它是连接层。Skills 则教导智能体如何使用这些工具。MCP 是“如何调用天气 API”,而技能则是“当用户询问旅行时,检查天气、比较目的地并格式化为行程单”。你两者都需要,而且它们可以自然地组合。
ADK 采用了相同的 agentskills.io 规范及其自身的技能集成。我面前就有一个现成的用例:一个博客写作智能体,它可以应用 SEO 检查清单、遵循风格指南,并根据需求生成新的能力,而无需在每次 LLM 调用中消耗 5,000 个 tokens 的上下文。
通过本文,你将了解如何:
- 解释**渐进式披露(progressive disclosure)**以及为什么它优于将所有内容塞进系统提示词
- 使用技能目录结构和导入项设置 ADK 项目
- 直接在 Python 中定义内联技能(inline skills),用于简单且稳定的规则
提示
- 渐进式披露将智能体知识分为三个层级加载(L1 元数据 → L2 指令 → L3 资源),仅在需要时获取每一层级。
- 一个拥有 10 个技能的智能体,每次调用只需约 1,000 tokens 的 L1 元数据,而不是单体系统提示词中约 10,000 tokens 的内容。
- ADK 的
SkillToolset会根据任何 SKILL.md 文件集合自动生成三个工具(list_skills、get_skill_details、load_skill_resource)。- 内联技能是最简单的模式 —— 一个包含
name、description和instructions键的 Python 字典。
什么是技能,为什么它们很重要
渐进式披露是 Agent Skills 规范中定义的一种设计模式,智能体按三个层级加载知识:轻量级元数据 (L1)、完整指令 (L2) 和参考文件 (L3)。它只在需要时获取每个层级,而不是在每次 LLM 调用中加载所有指令。
赋予智能体领域知识的典型方法是将所有内容打包进系统提示词。合规规则、风格指南、API 参考、故障排除程序 —— 所有这些都连接成一个巨大的指令字符串。当你只有两三个功能时,这运作良好。但当功能达到十个时,无论用户的提问是否与这些指令相关,系统提示词都会在每一次 LLM 调用中消耗数千个 tokens。
技能通过 渐进式披露 解决了这个问题。智能体不再预先加载所有内容,而是只能看到技能名称和描述的轻量级列表。当智能体判定某个技能与当前查询相关时,它会显式加载该技能的完整指令。如果该技能引用了详细文档或模板,智能体也会按需获取这些内容。该规范定义了三个层级:
- L1 — 元数据(每个技能约 100 tokens):来自 SKILL.md frontmatter 的
name和description字段。启动时为所有技能加载。这是智能体扫描以判定相关性的“菜单”。 - L2 — 指令(建议 < 5,000 tokens):SKILL.md 的完整正文。仅在智能体激活特定技能时加载。
- L3 — 资源(按需加载):位于
references/、assets/或scripts/中的文件。仅在技能指令引用它们时加载。
以下是实际运作的情况。假设你要求智能体“为我的博客文章进行 SEO 审查”。在系统提示词方法中,智能体已经在上下文中拥有了所有技能指令 —— SEO 规则、风格指南、研究方法、技能创建模板 —— 无论它是否需要。而在渐进式披露模式下,流程会有所不同:
L1 — 智能体扫描技能列表(始终存在,4 个技能约 400 tokens):
seo-checklist: 博客文章的 SEO 优化检查清单。涵盖标题标签、元描述……
blog-writer: 包含结构模板和风格指南的博客文章写作技能……
content-research-writer: 创建基于研究并经过 SEO 优化的内容……
skill-creator: 根据需求创建符合 ADK 规范的新技能定义……
L2 — 智能体调用 load_skill("seo-checklist")(按需加载约 300 tokens):
在为 SEO 优化博客文章时,检查以下各项:
1. 标题:50-60 字符,主关键词靠近开头
2. 元描述:150-160 字符,包含行动呼吁(CTA)
3. 标题:H2/H3 层级,关键词出现在 2-3 个标题中
...
L3 — 如果技能引用了文件,智能体调用 load_skill_resource(仅在需要时加载):
load_skill_resource("seo-checklist", "references/seo-guidelines.md")
→ 返回完整的 SEO 指南文档
其他三个技能保持在 L1 层级 —— 智能体从未加载它们的指令,因为它识别出查询是关于 SEO 的,而不是写作或研究。为了说明节省的开销:一个拥有 10 个技能的智能体,如果每个技能平均有 1,000 tokens 的指令,那么在传统的系统提示词方法下,每次调用都会消耗约 10,000 tokens。而采用渐进式披露的相同智能体,每次调用起始仅需约 1,000 tokens 的 L1 元数据,然后仅加载它需要的技能。确切的节省取决于技能数量和每个技能被激活的频率,但这种模式始终能保持基础上下文的精简。
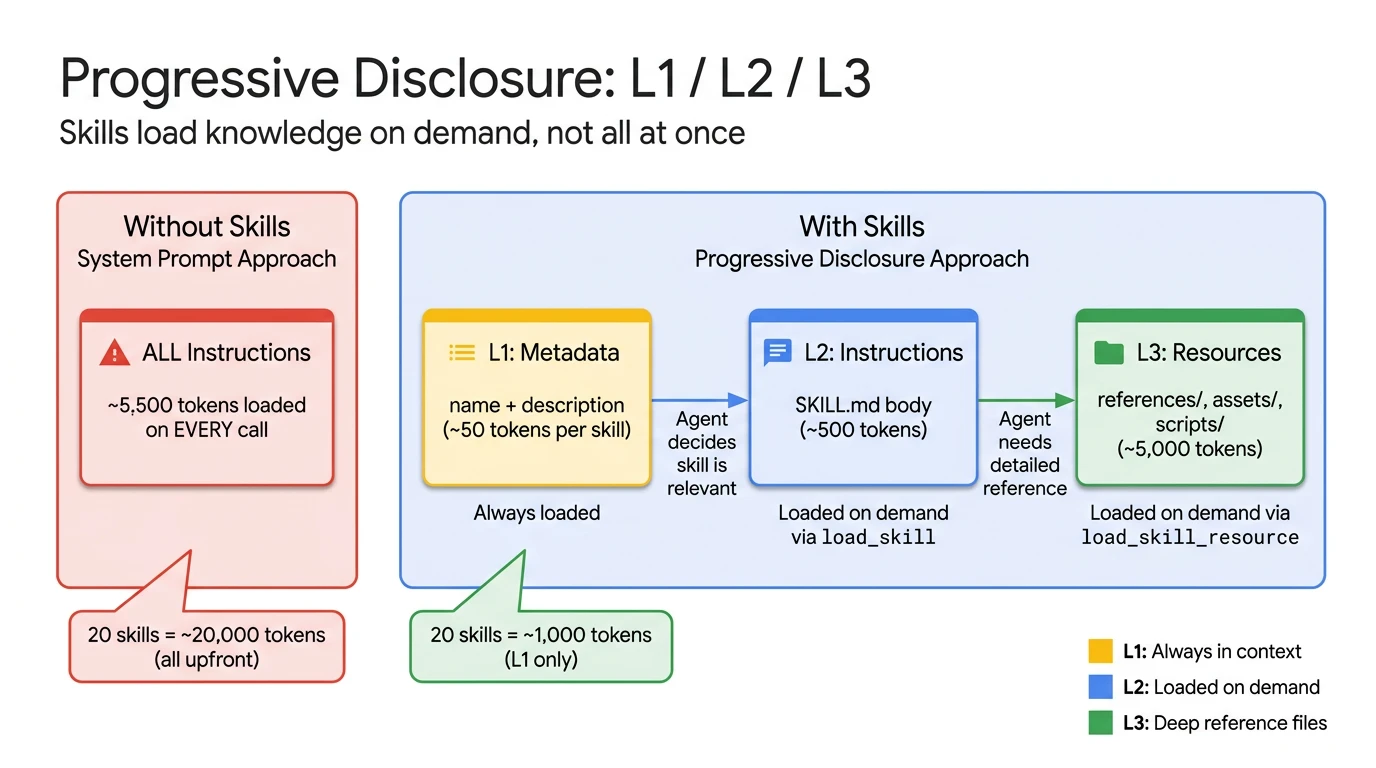
系统提示词方法在每次调用时加载所有技能指令。渐进式披露从 L1 元数据开始,仅在需要时加载 L2/L3。Token 估算基于 agentskills.io 规范范围。
ADK 通过 SkillToolset 类来实现这一点,该类在 ADK Python v1.25.0 中作为实验性功能引入。SkillToolset 将一个或多个技能封装为三个自动生成的工具 —— list_skills、load_skill 和 load_skill_resource —— 它们直接对应于 L1、L2 和 L3。本系列文章的后续部分将构建一个博客写作智能体,在四种技能模式中应用所有这三个层级。
ADK 项目设置
我们要构建的智能体使用单个 agent.py,并将四种技能接入一个 SkillToolset。每种模式在简洁性与可复用性之间进行了权衡,它们的排序使得每种模式都能在上一模式达到上限时接过接力棒。
| 模式 | 来源 | 用例 | 权衡 |
|---|---|---|---|
| 内联 (Inline) | Python 代码 | SEO 检查清单 —— 极少变更的稳定规则 | 编写最简单,但仅锁定于此智能体 |
| 基于文件 (File-based) | 本地目录 | 博客作者 —— 指令 + 风格指南参考 | 可在不同智能体间复用,需要目录结构 |
| 外部 (External) | 社区仓库 | 内容研究员 —— 从 awesome-claude-skills 下载 | 可在任何遵循规范的智能体中移植 |
| 元技能 (Meta) | 内联 + 参考 | 技能创建者 —— 根据需求生成新的 SKILL.md 文件 | 自我扩展的智能体,设计最复杂 |
这种演进过程本身就是一个故事。内联技能只需 10 行 Python 代码 —— 编写速度快,但知识仅存在于你的代码中。基于文件的技能将知识移动到包含 SKILL.md 和参考文档的目录中,使其具有可复用性。外部技能从他人的仓库中采用相同的目录格式。而元技能则完成了闭环:智能体自己按照相同的规范编写新的 SKILL.md 文件。
本文涵盖第一种模式。第二部分和第三部分将构建其余三种模式。
项目结构
官方 skills_agent 示例使用了这种布局。我们的博客写作智能体也遵循相同的模式。
app/
├── __init__.py
├── agent.py
├── .env
├── requirements.txt
└── skills/
├── blog-writer/
│ ├── SKILL.md
│ └── references/
│ └── style-guide.md
└── content-research-writer/
├── SKILL.md
└── references/
└── seo-guidelines.md
skills/ 目录存放基于文件的技能和外部技能。内联技能和元技能直接在 agent.py 中定义 —— 无需目录。
导入项与依赖
技能相关的导入项来自三个模块。
# agent.py
import pathlib
from google.adk import Agent
from google.adk.skills import load_skill_from_dir
from google.adk.skills import models
from google.adk.tools.skill_toolset import SkillToolset
models—— 用于在代码中定义技能的类:Skill、Frontmatter、Resourcesload_skill_from_dir—— 从磁盘目录读取技能(SKILL.md + 参考资料)SkillToolset—— 将一个或多个技能打包成智能体可调用的工具集
注意
一些外部资料显示为
from google.adk.tools.skill import SkillToolset。这两个导入路径都有效,但from google.adk.tools.skill_toolset import SkillToolset是 ADK 源码中的规范路径。
在运行前,请在 app/ 目录下的 .env 文件中设置你的 GOOGLE_API_KEY。通过 pip install google-adk python-dotenv 安装依赖。
框架已就绪。下一节将构建第一种技能模式 —— 四种模式中最简单的一种。
模式 1:内联技能
内联技能是最简单的 Agent Skills 模式 —— 它是一个直接在智能体代码中定义的 Python 字典,包含 name、description 和 instructions 键,非常适合不需要外部文件的、特定于项目的小型知识。
ADK 项目设置表格中的 SEO 检查清单就是最简单的案例 —— 极少变更的稳定规则,直接在 Python 中定义为内联技能。
# agent.py — 模式 1: 内联技能
seo_skill = models.Skill(
frontmatter=models.Frontmatter(
name="seo-checklist",
description=(
"博客文章的 SEO 优化检查清单。涵盖标题标签、"
"元描述、标题结构、关键词布局"
"和可读性最佳实践。"
),
),
instructions=(
"在为 SEO 优化博客文章时,检查以下各项:\n\n"
"1. **标题**:50-60 字符,主关键词靠近开头\n"
"2. **元描述**:150-160 字符,包含行动呼吁\n"
"3. **标题**:H2/H3 层级,关键词出现在 2-3 个标题中\n"
"4. **首段**:前 100 字内包含主关键词\n"
"5. **关键词密度**:1-2%,切勿生搬硬套或显得尴尬\n"
"6. **段落**:最多 2-3 句话,多使用列表符号\n"
"7. **链接**:2-3 个内部链接 + 3-5 个指向权威来源的外部链接\n"
"8. **图片**:Alt 文本包含关键词,经过压缩,名称具有描述性\n"
"9. **URL 别名**:短小、关键词丰富、使用连字符\n\n"
"根据每项内容审查内容并提出具体的改进建议。"
),
)
这三个字段对应于上一节提到的渐进式披露层级:
frontmatter(L1) ——Frontmatter需要两个字段,均在 agentskills.io 规范中定义:name—— 使用连字符命名法 (kebab-case),最多 64 个字符。对于基于文件的技能,必须与目录名匹配。description—— 最多 1024 个字符。这是 LLM 在 L1 发现阶段看到的内容 —— 它仅凭这段文字来决定是否加载该技能。规范建议包含“帮助智能体识别相关任务的具体关键词”。“博客文章的 SEO 优化检查清单”明确告诉了智能体该技能何时有用,而“一个有用的技能”则做不到。
instructions(L2) —— 智能体在调用load_skill("seo-checklist")时收到的实际知识。对于这个检查清单,编号列表中的九条规则就是智能体所需的全部内容。resources(L3, 可选) —— 以 Python 字符串形式嵌入的参考文件。内联技能可以附带这些文件以提供详细文档,但对于简单的检查清单,仅有指令就足够了。模式 4(在第三部分中)将使用此功能来嵌入 agentskills.io 规范本身。
当我询问智能体“你能为我的博客文章进行 SEO 审查吗?”时,它加载了 seo-checklist 技能并有条不紊地应用了每一项。
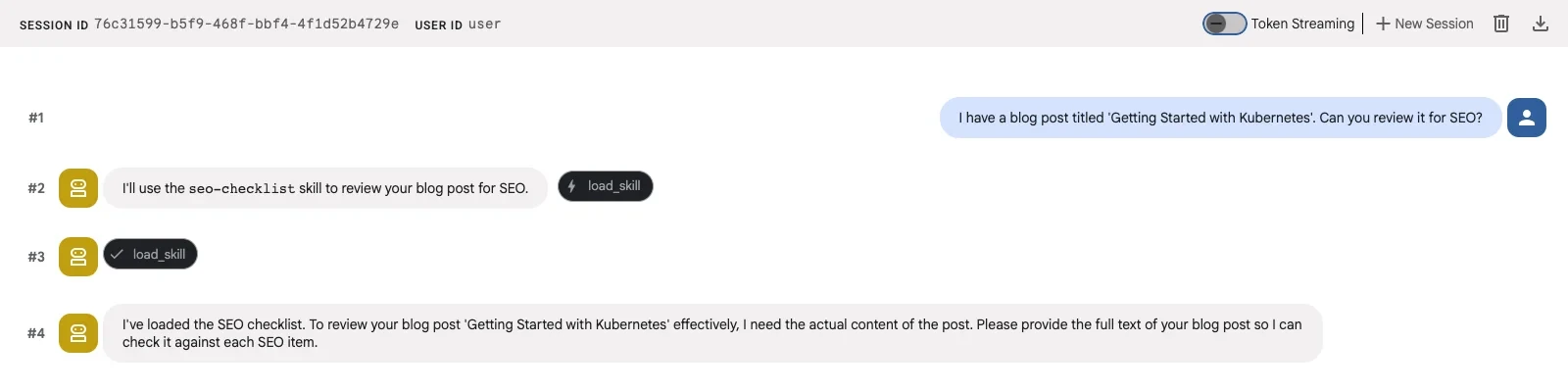
智能体调用 load_skill("seo-checklist") 来获取内联技能的 L2 指令,然后将检查清单的每一项应用于博客文章。
内联技能最适合不需要外部文件的简单、稳定规则。如果你的技能指令增长到几百字以上,或者你需要引用详细文档,那么基于文件的技能会是更好的选择。
下一步:基于文件和外部的 ADK 技能
我们已经介绍了概念基础 —— 什么是渐进式披露、它为什么重要,以及 ADK 的 SkillToolset 如何实现它 —— 并构建了最简单的模式:完全在 Python 中定义的内联技能。
在第二部分中,我们将超越 Python 字符串,进入包含参考文档的真实文件型技能,使用来自社区仓库的外部技能,并使用 SkillToolset 将所有内容连接到运行中的智能体。我们还将深入探究三个自动生成的工具,并观察多技能加载的实际运作。本文是完整智能体工程系列的一部分。欲了解更多关于 ADK 的内容,请查看标签存档。
继续阅读第二部分:基于文件的技能、外部技能与 SkillToolset 内部原理 →
常见问题解答
MCP 工具和 Agent Skills 之间有什么区别? MCP(模型上下文协议)工具赋予智能体“做”事情的能力 —— 调用 API、查询数据库、执行代码。Agent Skills 则赋予智能体“知识” —— 领域专业知识、指南以及按需加载的参考材料。它们是互补的:智能体使用 MCP 工具进行操作,使用技能来获取知识。
ADK 中渐进式披露的三个层级是什么? 第 1 层 (L1) 是轻量级元数据 —— 仅包含技能名称和描述,加载到每次调用中(每个技能约 100 tokens)。第 2 层 (L2) 是完整的指令集,仅在智能体决定需要该技能时加载。第 3 层 (L3) 是补充资源,如风格指南或 API 参考,仅针对特定的子任务加载。
渐进式披露能节省多少 tokens? 对于拥有 10 个技能的智能体,单体系统提示词方法每次调用大约消耗 10,000 tokens。采用渐进式披露后,智能体起始仅需约 1,000 tokens 的 L1 元数据,并根据需求加载 L2/L3 内容,从而将基础上下文减少约 90%。
我该什么时候使用内联技能 vs. 基于文件的技能? 使用内联技能处理不会在其他地方复用的、特定于项目的小型知识(例如,单个 SEO 检查清单)。当知识可在跨项目复用、需要补充文件(L3 资源)或应独立进行版本控制时,请使用基于文件的技能。
什么是 ADK 核心技能? ADK 核心技能是 Google 发布的官方技能,教导编码智能体(Gemini CLI、Claude Code、Cursor)如何编写 ADK 代码。它们使用与 SkillToolset 相同的 SKILL.md 格式和渐进式披露模式 —— 即设计模式文章中提到的工具封装器(Tool Wrapper)模式。使用 npx skills add google/adk-docs -y -g 安装它们。
参考资料
- ADK 智能体技能 —— SkillToolset 和渐进式披露的官方 ADK 文档
- Agent Skills 规范 —— 定义 SKILL.md 格式的开放标准
- 什么是 Agent Skills? —— 将技能视为可复用、与智能体无关的能力的概念性概述
- agentskills/agentskills —— 开源规范仓库和参考库
skills/models.py——Skill、Frontmatter、Resources类定义skills_agent示例 —— 包含内联 + 文件型技能的官方 ADK 示例- @liamottley_ — “SaaS 正在被 SKILL.md 文件所取代” —— 562 个互动
- @Pavan_Belagatti — MCP vs. Skills —— 明确的 MCP/Skills 区分
- ADK 核心技能 —— 构建 ADK 智能体的官方技能
[📦
配套仓库
克隆仓库并使用 adk web 运行内联技能模式。
→](https://github.com/lavinigam-gcp/build-with-adk/tree/main/adk-agent-skills-tutorial) [📚
ADK 技能文档
SkillToolset、渐进式披露和技能加载的官方指南
→](https://google.github.io/adk-docs/skills/) [🌐
Agent Skills 规范
已被 30 多个智能体采用的 SKILL.md 格式开放标准