昨晚,我又一次在一场路演之夜中被拒了。那还只是预面试阶段,问题也不在我的产品上。我已经有 MRR 了,也已经有每天都依赖它的用户。
对方给出的反馈很简单:“那你到底为什么还需要融资?”
每次我试图把自己的想法做大时,都会反复听到这句话。精益运营几乎已经写进了我的 DNA。你可能用过我做的一些工具,比如 websequencediagrams.com;也可能没用过我做的一些小众产品,比如 eh-trade.ca。这种对效率的执念,确实会带来成功的 bootstrap,但说实话,很多 VC 讨厌 这一点。
把成本压到几乎为零,带来的 runway,其实和你拿到一笔百万美元融资、却以极高速度烧钱差不多。这样压力更小,架构也会保持得极其简单,还能让你在没有董事会在背后催命的情况下,有足够时间去找到 product-market fit。
如果你已经受够了现代那套“企业级”样板做法,下面就是我如何几乎不花什么钱来搭建公司的完整打法。
使用精简的服务器
2026 年,启动一个 Web 应用最天真的方式,是先点开 AWS,配一套 EKS 集群、拉一个 RDS 实例、再设一个 NAT Gateway,最后在还没有一个用户点开你的 landing page 之前,就先不小心花掉每月 300 美元。
更聪明的办法,是租一台单独的虚拟专用服务器(VPS)。
我做的第一件事,就是找一台便宜又可靠的机器。忘掉 AWS 吧。你大概率根本用不上它,而且它的控制面板就像一个专门用来诱导你升级账单的迷宫。我用的是 Linode 或 DigitalOcean。每月花费不要超过 5 到 10 美元。
1GB 内存对现代 Web 开发者来说听上去可能很吓人,但如果你知道自己在做什么,其实完全够用。如果你只是想多一点余量,加个 swapfile 就行。
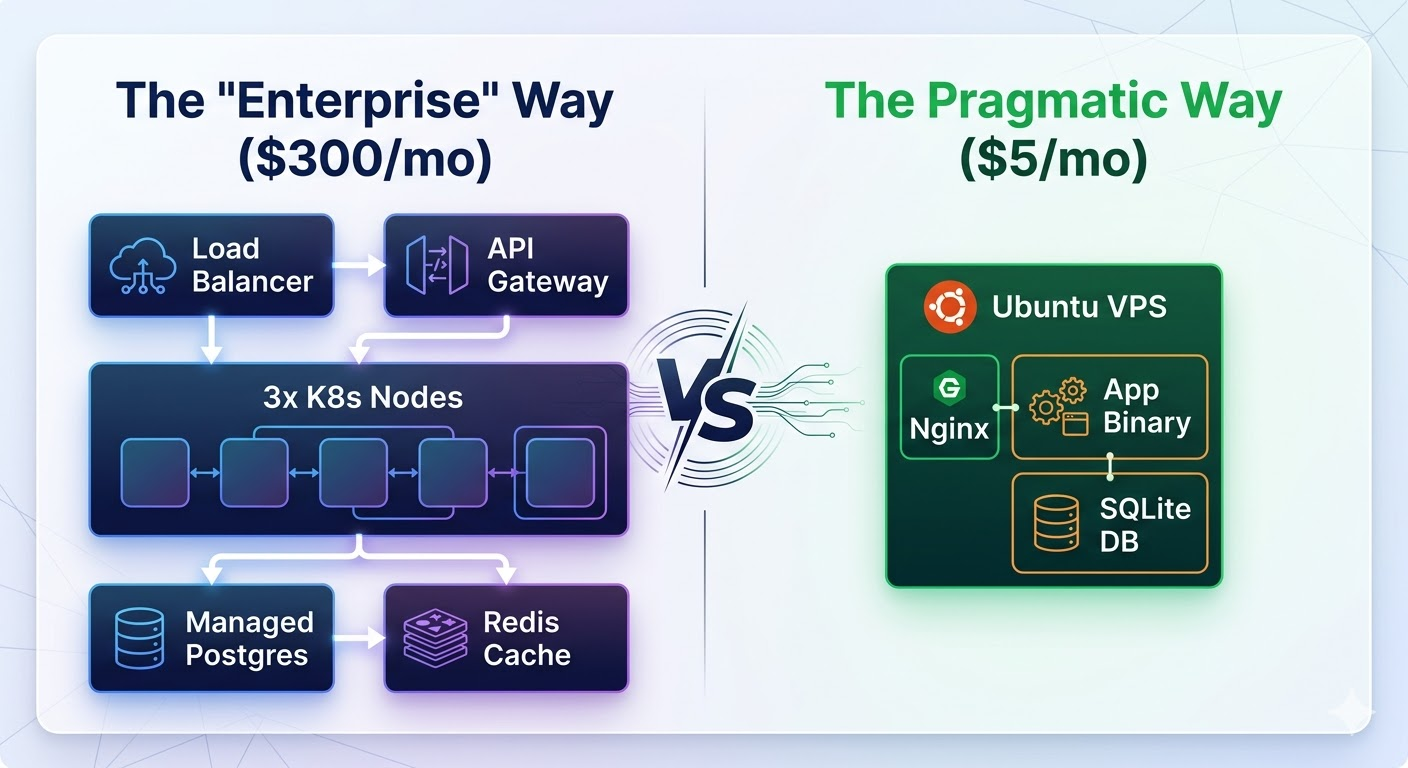
目标是服务请求,而不是维护基础设施。只有一台服务器时,你会清楚知道日志在哪、它为什么崩、以及该怎么把它重启起来。
使用精简的语言
接下来你就有约束了。你只有 1GB 内存。你当然可以用 Python 或 Ruby 做主后端语言——但为什么要这么做?光是启动解释器、管理 gunicorn worker,就会吃掉你一半内存。
我用 Go 写后端。
Go 在 Web 场景里的性能高得多,还是强类型语言,而且——对 2026 年尤其重要——LLM 对它的理解也非常轻松。但 Go 真正的魔力在于部署过程。没有 pip install 的依赖地狱,没有虚拟环境。你只需要在自己电脑上把整个应用编译成一个静态链接的单一二进制文件,用 scp 传到你那台 5 美元的服务器上,然后直接运行。
下面就是一个完整、可用于生产环境的 Go Web 服务器长什么样。不需要任何臃肿框架:
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, your MRR is safe here.")
})
// This will comfortably handle 10,000s of requests per second
// on a potato.
http.ListenAndServe(":8080", nil)
}
对长时任务使用本地 AI
如果你家里某个角落放着一张显卡,那你其实已经拥有了无限的 AI 积分。
我在做 eh-trade.ca 的时候,碰到过一个很具体的问题:我需要对上千家公司做深入、偏定性的股市研究,并总结海量季度财报。最天真的解决办法,就是把所有东西都扔给 OpenAI API。我本来可以在 API 积分上花掉几百美元,最后却只发现是自己的 prompt loop 里有个逻辑 bug,导致整批任务都得重跑一遍。
所以我改用了 VLLM,跑在一张我从 Facebook Marketplace 买来的、落灰已久的 900 美元显卡上(RTX 3090,24GB VRAM)。这当然是一笔前期投入,但至少从此以后,我再也不用为了批处理任务一次次向 AI 提供商交“过路费”。
在本地 AI 这件事上,你有一条很清晰的升级路径:
- 先从 Ollama 开始。 它一条命令就能装好(
ollama run qwen3:32b),还能让你立刻试几十种模型。它是迭代 prompt 的理想环境。 - 生产环境切到 VLLM。 一旦你的系统已经跑通,Ollama 就会变成并发请求的瓶颈。VLLM 会把你的 GPU 锁定在一个模型上,但它因为使用了 PagedAttention,所以速度会快得多。你只要把系统设计成一次并发发送 8 或 16 个异步请求,VLLM 就会在 GPU 显存里自动把它们合批处理,而这 16 个请求完成的时间,差不多只相当于处理 1 个请求。
- 更高级的需求就用 Transformer Lab。 如果你需要做模型预训练或微调,Transformer Lab 能让你更容易地在本地硬件上完成这些工作。
为了管理这一切,我做了 laconic,这是一个 agentic researcher,专门针对受限的 8K context window 做过优化。它管理 LLM 上下文的方式,很像操作系统管理虚拟内存:把对当前任务无关的对话包袱“分页换出”,只把最关键的事实保留在当前活跃的上下文窗口里。
我还用了 llmhub。它把任意 LLM 都抽象成一个简单的 provider / endpoint / apikey 组合,不管模型是在我桌子底下本地运行,还是在云端,它都能优雅地处理文本和图像 IO。
用 OpenRouter 作为你的快速 / 智能 LLM 出口
你不可能把所有事情都放在本地做。有些时候,面向用户的低延迟聊天交互,就是需要 Claude 3.5 Sonnet 或 GPT-4o 这类最前沿模型的推理能力。
与其同时管理 Anthropic、Google 和 OpenAI 的账单账户、API key 与限流规则,我直接用 OpenRouter。你只需要在代码里写一套兼容 OpenAI 的集成,就能立刻接入所有主流前沿模型。
更重要的是,它还能带来无缝的 fallback routing。比如 Anthropic 的 API 在某个周二下午挂了(这事确实会发生),我的应用就会自动切换到一个等价的 OpenAI 模型。用户根本看不到错误页面,而我也不用自己写复杂的重试逻辑。
用 Copilot,而不是那些被吹上天的 AI IDE
每周都有新的、贵得离谱的模型发布。我总听到开发者说,他们每个月光是 Cursor 订阅和 Anthropic API key,就要花掉几百美元,只为了让 AI 帮他们写样板代码。
而我这边,整天都在用 Claude Opus 4.6,一个月账单却 barely 到 60 美元。我的秘诀?我在利用微软的定价模型。
我在 2023 年买了 GitHub Copilot 订阅,把它接进标准版 VS Code 之后就再也没离开过。后来我也试过 Cursor 和其他那些一度凭借 agentic coding 短暂领先的花哨分叉产品,但 Copilot Chat 总会追上来。
这里有个你可能忽略的关键点:微软似乎是按请求收费,而不是按 token 收费。所谓一个“请求”,其实就是我在聊天框里输入的内容。哪怕 agent 接下来花 30 分钟啃完整个代码库、梳理依赖、修改上百个文件,我付出的价格依然大概只有 0.04 美元。
最优策略其实很简单:写出极其详细、带严格成功标准的 prompt(反正这本来就是最佳实践),告诉 agent “keep going until all errors are fixed”,然后按下回车,去冲一杯咖啡,让 Satya Nadella 替你补贴算力成本。
全部都用 SQLite
我开启一个新项目时,主数据库总是先用 sqlite3。先别急着反驳,这并没有你想的那么疯狂。
企业软件思维会告诉你,数据库必须是一个独立进程的服务器。但事实是,一个本地 SQLite 文件,通过 C 接口或内存进行通信,其速度比起通过 TCP 网络跳转去连远程 Postgres 服务器,快了不止一个数量级。
“那并发怎么办?”你可能会问。很多人以为 SQLite 每次写入都会锁住整个数据库。这是错的。你只需要打开 Write-Ahead Logging(WAL)。在打开数据库时执行一次下面这段 pragma:
PRAGMA journal_mode=WAL;
PRAGMA synchronous=NORMAL;
搞定。读不再阻塞写,写也不再阻塞读。这样一来,你只靠一份放在 NVMe 硬盘上的 .db 文件,就能轻松承载成千上万的并发用户。
因为在基于 SQLite 的项目里,做用户认证往往是最烦人的部分,所以我干脆写了一个库:smhanov/auth。它能直接接到你正在使用的数据库里,负责管理用户注册、会话和密码重置。它甚至支持用户通过 Google、Facebook、X,或者他们公司自有的 SAML 提供商登录。没有臃肿依赖,只有简单、可审计的代码。
结语
科技行业总想让你相信:要做成一门真正的生意,你就必须上复杂编排、每月巨额的 AWS 账单,以及数百万美元的风险投资。
其实并不需要。
只要用一台 VPS、静态编译的二进制文件、本地 GPU 去处理批量 AI 任务,再加上 SQLite 的原始速度,你就能 bootstrap 出一家高度可扩展的初创公司,而它每月成本甚至低于几杯咖啡的钱。你等于是为项目加上了无限 runway,让自己有时间真正去解决用户的问题,而不是天天焦虑 burn rate。
如果你也对精益运营感兴趣,可以去看看我在 GitHub 上的 auth 库和那些 agent 实现。我会在评论区里待着——欢迎告诉我你是怎么压低服务器成本的,或者直接告诉我,我这套说法到底哪里错了。